Increasingly more of the research community is getting on board with the idea that including sex and/or gender in health research is important. Historically, women have had the short end of the stick when it comes to health research, as male animals and men have been the default for clinical trials, and studies focused on women’s health have been chronically underfunded. This has led to a lower quality of care for women in diverse areas; from male only crash-test dummies leading to more seatbelt related trauma for women and children, drugs having different efficacies or modes of action in women compared to men, and the symptoms of heart attack being different for women leading to lower rates of diagnosis and treatment, to name only a few. Consequently, the NIH and CIHR have introduced policies requiring sex and/or gender-based analyses for studies involving human health (even when animal models are being used).
Increasingly more of the research community is getting on board with the idea that including sex and/or gender in health research is important. Historically, women have had the short end of the stick when it comes to health research, as male animals and men have been the default for clinical trials, and studies focused on women’s health have been chronically underfunded. This has led to a lower quality of care for women in diverse areas; from male only crash-test dummies leading to more seatbelt related trauma for women and children, drugs having different efficacies or modes of action in women compared to men, and the symptoms of heart attack being different for women leading to lower rates of diagnosis and treatment, to name only a few. Consequently, the NIH and CIHR have introduced policies requiring sex and/or gender-based analyses for studies involving human health (even when animal models are being used).
The problem is that neither the NIH or CIHR are particularly good at providing guidance for how to incorporate both sexes into a study (leaving off any additional issues of gender), especially in terms of how many of each must be included. This has led to studies with the same total N as previously, but now split between the sexes. Much of the time this leads to pooling the sexes in analysis, and does not provide enough power to determine if there are sex-differences present, and potentially worsens our ability to properly understand health issues in either sex. In contrast, there are some instances where sex-specific analysis may actually be preferred to fully understand the processes involved: e.g. when investigating sex-specific cancers, or other conditions that have much higher prevalence in one sex vs. the other. My colleague Dr Liisa Galea recently published an article in Vice where she excellently summarizes these issues. It’s worth the read!
I looked at some of the guidance from CIHR about accounting for sex in animal research. Understandably, scientists like to use the fewest number of animals possible, both from cost and ethics perspectives. To this end, CIHR published this piece, entitled “If I include female animals, do I need to double my sample size?”. The bottom line in the article is that researchers do not need to double the sample size, and may not even need to increase it at all. The problem with this advice is that it implicitly assumes that any difference in treatment effect between the sexes is very large, and their suggestions would leave studies with subtler differences underpowered to detect them.
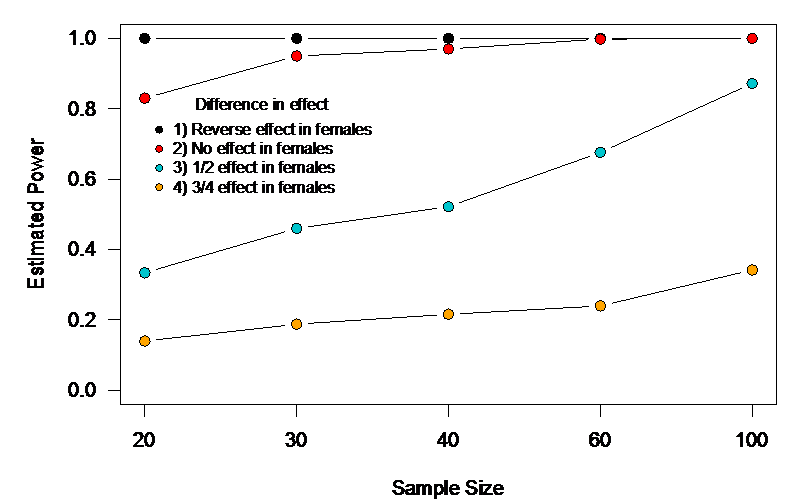
To determine how big a problem this might be, I simulated 2×2 ANOVA experiments as outlined in their example. First, I used the same sample size they mention: 20 total, 10 females, 10 males, with 5 each of males and females in the control and treatment groups. I then varied the sample size (30, 40, 60, 100) keeping the same factorial design, and also varied the difference in treatment effect between males and females. These differences in effect were: 1) treatment effect is exactly reversed in females compared to males, 2) the treatment has an effect in males, but none in females, 3) the treatment is half as effective in females compared to males, and 4) the treatment is ¾ as effective in females compared to males. I found that while we had excellent power to detect scenarios 1 and 2, power was terrible for 3 until we reached a sample size of 100, and was terrible for 4 across the board (Fig.1). I chose parameter values for the variables in the model that resulted in very large effect sizes for both sex and treatment effects. That means that with the smaller sample sizes, if the smaller effect interaction was non-significant, researchers would still find a significant treatment effect and would erroneously conclude that it was the same for both sexes. So, unless we’re only interested in differences in treatment effect between the sexes that are huge, this guidance might result in studies that fail to find sex differences that are truly clinically relevant. One could argue that this might be okay in primary animal studies, but the danger is that the lack of detected sex difference might trickle up through to human trials where no difference in efficacy between the sexes might become the baseline assumption.